هوش مصنوعی یا AI فناوری است که کامپیوترها و ماشین ها را قادر می سازد تا هوش انسان و قابلیت های حل مساله را شبیه سازی نمایند. هوش مصنوعی به تنهایی یا در ترکیب با فناوری های دیگری همچون سنسورها، موقعیت یاب جغرافیایی، رباتیک و غیره می تواند وظایفی را انجام دهد که در حالت عادی به هوش و مداخله انسان نیاز دارد. دستیارهای دیجیتال، سیستم مکان یاب جغرافیایی، وسایل خودران و ابزارهای مولد هوش مصنوعی (همچون Chat GPT) مثال های معدودی از هوش مصنوعی هستند که در اخبار روزانه و زندگی روزمره خود درباره آنها می شنویم و با آنها در گیریم.
به عنوان رشته ای از علوم کامپیوتر، هوش مصنوعی شامل یادگیری ماشین و یادگیری عمیق است. این رشتهها توسعه الگوریتمهای هوش مصنوعی را در بر می گیرند که بر اساس فرآیندهای تصمیمگیری مغز انسان مدلسازی شدهاند و میتوانند از دادههای موجود «یاد بگیرند» و در طول زمان طبقهبندی یا پیشبینی دقیقتری را انجام دهند. هوش مصنوعی نوسانات تبلیغاتی زیادی را پشت سر گذاشته است، اما حتی برای افراد شکاک هم انتشار ChatGPT نقطه عطف چشمگیری بود. آخرین باری که هوش مصنوعی مولد در این وسعت پدیدار شد، به پیشرفت هایی در قوه بینایی کامپیوتر برمی گردد. اما در حال حاضر پیشرفت رو به جلو در مورد پردازش زبان طبیعی (NLP) است. امروزه، هوش مصنوعی مولد نه تنها زبان انسان، بلکه انواع دیگر دادهها از جمله تصاویر، ویدئو، کد های نرمافزار و حتی ساختارهای مولکولی را میتواند یاد بگیرد و ترکیب کند. برنامه های کاربردی برای هوش مصنوعی هر روز در حال افزایش هستند. اما با افزایش تبلیغات در مورد استفاده از ابزارهای هوش مصنوعی در تجارت، بحث و گفتگوها پیرامون اخلاق در هوش مصنوعی و هوش مصنوعی مسئولیت پذیر بسیار حائز اهمیت شده است.
در مورد هوش مصنوعی و عصر جدیدی در منابع انسانی بخوانید
تاریخچه هوش مصنوعی
این ایده که «یک ماشین می تواند فکر کند» به یونان باستان برمی گردد. اما از زمان ظهور محاسبات الکترونیکی، وقایع و تحولات مهم در تکامل هوش مصنوعی به صورت زیر می باشد:
سال 1950: آلن تورینگ مقاله «ماشین های محاسباتی و هوش» را منتشر نمود. در این مقاله، تورینگ که معروف به شکستن کد انیگمای آلمان در طول جنگ جهانی دوم بود و اغلب به عنوان «پدر علوم کامپیوتر» شناخته می شود، این سوال را مطرح می کند: «آیا ماشین ها می توانند فکر کنند؟» بنابراین او آزمایشی را ارائه می دهد که اکنون به نام «آزمون تورینگ» معروف است، که در آن یک بازجوی انسانی سعی می کند بین پاسخ متنی کامپیوتری و انسانی تمایز قائل شود. از وقتی که این آزمون انجام شده، تحلیل های موشکافانه ای منتشر شده است ولی این موضوع کماکان به عنوان بخش مهمی در حوزه هوش مصنوعی و تا زمانی که از ایده های زبان شناسی استفاده می کند، به عنوان یک مفهوم ماندگار در حوزه فلسفه باقی مانده است.

سال 1956: جان مک کارتی در اولین کنفرانس هوش مصنوعی در کالج دارتموث اصطلاح «هوش مصنوعی» را ابداع کرد (مک کارتی به توسعه زبان Lisp ادامه داد). در اواخر همان سال، آلن نیوول، جی سی شاو و هربرت سایمون، نظریه پرداز منطقی (Logic Theorist) را ارائه دادند که اولین برنامه نرم افزاری هوش مصنوعی در حال اجرا بود.
سال 1967: فرانک روزنبلات (Frank Rosenblatt) اولین رایانه مبتنی بر یک شبکه عصبی به نام Mark 1 Perceptron را ساخت که با آزمون و خطا یاد می گرفت. فقط یک سال بعد، ماروین مینسکی و سیمور پیپرت کتابی با عنوان پرسپترونها (Perceptrons) منتشر کردند که نه تنها به کار برجسته ای در مورد شبکههای عصبی تبدیل شد بلکه حداقل برای مدتی گفتمان مقابل پروژههای تحقیقاتی شبکههای عصبی آینده بود.
دهه 1980: شبکههای عصبی که از یک الگوریتم پس انتشار (backpropagation algorithm) برای یادگیری خود استفاده میکردند، به طور گسترده در کاربردهای هوش مصنوعی مورد استفاده قرار گرفتند.
سال 1995: استوارت راسل و پیتر نورویگ کتاب هوش مصنوعی: رویکردی مدرن (Artificial Intelligence: A Modern Approach) را منتشر کردند، که به یکی از کتابهای درسی پیشرو در مطالعه هوش مصنوعی تبدیل شد. در آن کتاب، آنها به چهار هدف یا تعریف بالقوه هوش مصنوعی می پردازند، که سیستم های کامپیوتری را بر اساس تقابل عقلانیت و تفکر با عمل تفکیک می کند.سال 1997: دیپ بلو از IBM در یک مسابقه شطرنج (و مسابقه مجدد) قهرمان شطرنج جهان، گری کاسپاروف را شکست داد.

سال 2004: جان مک کارتی مقاله ای با عنوان هوش مصنوعی چیست؟ (What Is Artificial Intelligence?) چاپ و تعریفی را که اغلب از هوش مصنوعی استناد می شود را پیشنهاد کرد.
سال 2011: IBM Watson قهرمانان برنامه تلویزیونی Jeopardy (Ken Jennings and Brad Rutter) را شکست داد.

سال 2015: ابرکامپیوتر Minwa Baidu از نوع خاصی از شبکه عصبی عمیق به نام شبکه عصبی کانولوشن برای شناسایی و دستهبندی تصاویر با دقت بالاتری نسبت به انسان معمولی استفاده میکند.
سال 2016: برنامه AlphaGo DeepMind که توسط یک شبکه عصبی عمیق پشتیبانی می شود، لی سدول، قهرمان جهانی بازی Go را در یک مسابقه شکست داد. این پیروزی با توجه به تعداد زیادی حرکات ممکن در طول بازی (بیش از 14.5 تریلیون تنها پس از چهار حرکت!) قابل توجه است. بعداً گوگل DeepMind را به مبلغ 400 میلیون دلار خریداری کرد.

سال 2023: افزایش مدلهای زبانی کلان (large language models) یا LLMها، مانند ChatGPT، تغییری عظیم در عملکرد هوش مصنوعی و پتانسیل آن برای افزایش ارزش سازمانی ایجاد کرد. با این شیوههای جدید هوش مصنوعی مولد، میتوان مدلهای یادگیری عمیق را روی مقادیر زیادی داده خام و بدون برچسب از قبل آموزش داد.
انواع هوش مصنوعی: هوش مصنوعی ضعیف در مقابل هوش مصنوعی قوی
هوش مصنوعی ضعیف که با آن هوش مصنوعی ظریف یا باریک (ANI) نیز گفته می شود، یک نوع هوش مصنوعی است که برای انجام وظایف خاص آموزش دیده و بر آنها تمرکز دارد. هوش مصنوعی ضعیف بیشتر هوش مصنوعی که امروز ما را احاطه کرده است به جلو پیش می برد. واژه «باریک» ممکن است توصیف مناسب تری برای این نوع هوش مصنوعی باشد چرا که می تواند هر چیزی باشد به جز صفت ضعیف بودن و برخی از برنامه های بسیار قدرتمند مانند سیری اپل، الکسای آمازون، واتسون و وسایل نقلیه خودران را پشتیبانی می کند.
هوش مصنوعی قوی از هوش عمومی مصنوعی (AGI- artificial general intelligence) و اَبَر هوش مصنوعی (ASI- artificial super intelligence) تشکیل شده است. AGI یا هوش مصنوعی عمومی، شکلی نظری از هوش مصنوعی است که در آن یک ماشین دارای هوشی برابر با انسان است و می تواند با خودآگاهی، از وجود خود مطلع بوده و خودشناسا باشد به طوری که توانایی حل مسائل، یادگیری و برنامه ریزی برای آینده را داشته باشد. ASI که با عنوان ابر هوش نیز شناخته می شود، از هوش و توانایی مغز انسان پیشی می گیرد. در حالی که هوش مصنوعی قوی هنوز کاملاً تئوریک می باشد و تاکنون هیچ نمونه عملی مورد استفاده قرار نگرفته است، این بدان معنا نیست که محققان هوش مصنوعی نیز در حال توسعه آن نباشند. ضمناً، بهترین نمونه های ASI ممکن است داستان های علمی-تخیلی باشد، مانند HAL، دستیار کامپیوتر مافوق بشری و سرکش یا ادیسه فضایی 2001.
یادگیری ماشین چیست و چگونه کار می کند؟
یادگیری ماشین (ML) شاخهای از هوش مصنوعی (AI) و علوم کامپیوتر است که بر استفاده از دادهها و الگوریتمها تمرکز دارد تا هوش مصنوعی را قادر سازد از روش یادگیری انسانها، تقلید کند و به تدریج دقت آن را بهبود بخشد.
UC Berkeley سیستم یادگیری الگوریتم یادگیری ماشین را به سه بخش اصلی تقسیم می کند:
- فرآیند تصمیم گیری: به طور کلی، الگوریتم های یادگیری ماشین برای پیش بینی یا طبقه بندی استفاده می شود. بر اساس داده های ورودی، که می توانند دارای برچسب یا بدون برچسب باشند، این الگوریتم به طور تقریبی الگویی را در داده ها ایجاد می کند.
- تابع خطا: یک تابع خطا توان پیش بینی مدل را ارزیابی می کند. اگر نمونه های شناخته شده وجود داشته باشد، تابع خطا می تواند مبنایی برای مقایسه دقت ارزیابی مدل داشته باشد.
- فرآیند بهینه سازی مدل: اگر مدل بتواند با مجموعه نقاطِ آموزشی داده ها تناسب بهتری داشته باشد، آنگاه اختلاف بین نمونه شناخته شده و مدل تخمینی تعدیل و کاهش می یابند. الگوریتم، این فرآیند تکراری یعنی «ارزیابی و بهینه سازی» را مدام تکرار می کند و وزن ها را به طور مستقل تا رسیدن به دقت نهایی به روزرسانی می نماید.
روش های یادگیری ماشین
مدل های یادگیری ماشینی به سه دسته اصلی تقسیم می شوند:
یادگیری ماشینی با ناظر: یادگیری با ناظر که با عنوان یادگیری ماشینی نظارت شده نیز شناخته می شود، با استفاده از مجموعه داده های برچسب گذاری شده برای آموزش الگوریتم ها جهت طبقه بندی داده ها یا پیش بینی دقیق نتایج، تعریف می شود. همانطور که داده های ورودی به مدل وارد می شود، مدل دقت خود را تا زمانی که برازش مناسبی انجام شود، تنظیم می کند. این کار به عنوان بخشی از فرآیند راستی آزمایی متقاطع رخ می دهد (برای حصول اطمینان از اینکه مدل از برازش بیش از حد یا برازش ناقص اجتناب کند). یادگیری تحت ناظر به سازمان ها کمک می کند تا انواع مسائل دنیای واقعی را حل کنند، مانند طبقه بندی هرزنامه ها در یک پوشه جداگانه از صندوق ورودی ایمیل شما. برخی از روشهای مورد استفاده در یادگیری نظارت شده عبارتند از: شبکههای عصبی، رگرسیون خطی، رگرسیون لجستیک، جنگل تصادفی و ماشین بردار پشتیبان (SVM).
یادگیری ماشینی بدون ناظر: یادگیری بدون ناظر، که به عنوان یادگیری ماشین بدون نظارت نیز شناخته می شود، از الگوریتم های یادگیری ماشین برای تجزیه و تحلیل و خوشه بندی مجموعه داده های بدون برچسب (زیر مجموعه هایی به نام خوشه ها) استفاده می کند. این الگوریتم ها، الگوهای پنهان یا گروه بندی داده ها را بدون دخالت انسان کشف می کنند. توانایی این روش برای کشف شباهتها و تفاوتهای موجود در اطلاعات، آن را برای تجزیه و تحلیل دادههای اکتشافی، استراتژیهای فروش متقابل، بخشبندی مشتری و تشخیص تصویر و الگو ایدهآل میکند. همچنین برای کاهش تعداد ویژگی های یک مدل از روش فرآیند کاهش ابعاد (dimensionality reduction) استفاده می شود. تجزیه و تحلیل مؤلفه اصلی (Principal component analysis) و تجزیه ارزش منفرد (singular value decomposition) دو رویکرد رایج برای این کار هستند. سایر الگوریتمهای مورد استفاده در یادگیری بدون ناظر شامل شبکههای عصبی، خوشهبندی میانگین های k و روشهای خوشهبندی احتمالی می باشند.
یادگیری با شبه ناظر: یادگیری نیمهنظارتی یا با شبه ناظر، حالت بینابینی میان یادگیری با ناظر و بدون ناظر است. در طول آموزش، از مجموعه ای کوچک از داده های برچسبدار برای طبقهبندی و استخراج ویژگی مجموعه ای از داده بزرگتر و بدون برچسب استفاده میشود. یادگیری نیمه نظارتی می تواند مشکل کمبود داده های برچسب گذاری شده و پرهزینه را برای الگوریتم یادگیری نظارت شده حل نماید.
یادگیری ماشینی تقویتی
یادگیری ماشینی تقویتی یک مدل یادگیری ماشینی است که شبیه به یادگیری نظارت شده است، اما الگوریتم با استفاده از داده های نمونه آموزش داده نمی شود. این مدل با استفاده از آزمون و خطا یاد می گیرد و دنباله ای از نتایج موفقیت آمیز برای ایجاد بهترین توصیه یا خط مشی برای یک مساله خاص، تقویت می شود. سیستم IBM Watson که برنده برنامه تلویزیونی Jeopardy در سال 2011 شد، مثال خوبی است. این سیستم از یادگیری تقویتی استفاده میکرد تا یاد بگیرد که چه زمانی باید برای پاسخ (یا سؤالی که مطرح شده بود)، کدام مربع را روی تخته انتخاب کند و چقدر شرط بندی نماید.
الگوریتم های رایج یادگیری ماشین
تعدادی از الگوریتم های رایج یادگیری ماشین به شرح زیر می باشند:
شبکه های عصبی: شبکه های عصبی عملکرد مغز انسان را شبیه سازی می کنند ولی با تعداد زیادی گره پردازشی. شبکه های عصبی در تشخیص الگوها خوب هستند و نقش مهمی در کاربردهایی چون ترجمه زبان طبیعی، تشخیص تصویر، تشخیص گفتار و ایجاد تصویر دارند.
رگرسیون خطی: این الگوریتم برای پیش بینی مقادیر عددی بر اساس رابطه خطی بین مقادیر مختلف بکار می رود. به عنوان مثال، این تکنیک می تواند برای پیش بینی قیمت خانه بر اساس داده های تاریخی و گذشته نگر برای منطقه ای خاص مورد استفاده قرار گیرد.
رگرسیون لجستیک: این الگوریتم یادگیری با ناظر برای متغیرهای واکنشی طبقهای (مانند پاسخهای «بله/خیر» به سؤالات) پیشبینی انجام می دهد و می توان از آن برای برنامه هایی مانند طبقه بندی هرزنامه ها و کنترل کیفیت در خط تولید استفاده نمود.
خوشه بندی: الگوریتم های خوشه بندی با استفاده از یادگیری بدون ناظر، می توانند الگوهای موجود در داده ها را شناسایی کنند تا بتوان آنها را گروه بندی نمود. رایانه ها می توانند با شناسایی داده هایی که انسان ها نادیده گرفته اند، به دانشمندان داده کمک کنند.
درخت تصمیم: درخت تصمیم را می توان هم برای پیش بینی مقادیر عددی (رگرسیون) و هم برای طبقه بندی داده ها استفاده کرد. درخت تصمیم از یک دنباله شاخه بندی (branching sequence) از تصمیمات مربوطه استفاده می کند که می تواند با یک نمودار درختی نمایش داده شود. یکی از مزایای درخت تصمیم این است که بر خلاف جعبه سیاه اعتبارسنجی و ارزیابی آنها آسان است.
جنگلهای تصادفی: در یک جنگل تصادفی، الگوریتم یادگیری ماشین یک مقدار یا دسته را با ترکیب نتایج تعدادی درخت تصمیم پیشبینی میکند.
مزایا و معایب الگوریتم های یادگیری ماشینی
با توجه به بودجه شما و میزان سرعت و دقت مورد نیاز، هر نوع الگوریتم (با ناظر، بدون ناظر، نیمه نظارتی یا تقویتی) مزایا و معایب خاص خود را دارد. به عنوان مثال، الگوریتم های درخت تصمیم هم برای پیش بینی مقادیر عددی (مسائل رگرسیون) و هم برای دسته بندی داده ها استفاده می شود. درختان تصمیم از یک دنباله شاخه ای از تصمیمات مرتبط استفاده می کنند که ممکن است با یک نمودار درختی نشان داده شود. مزیت اصلی درختان تصمیم این است که اعتبارسنجی و ارزیابی آنها آسانتر از شبکه عصبی است ولی خبر بد این است که آنها می توانند ناپایدارتر از سایر پیش بینی کننده های تصمیم باشند.
به طور کلی، یادگیری ماشینی مزایای زیادی دارد که کسب و کارها می توانند از آنها بهره برداری کنند. یادگیری ماشینی الگوها و روندها را در حجم عظیمی از دادهها که ممکن است انسان اصلاً آنها را تشخیص ندهد، شناسایی میکند. این تجزیه و تحلیل به مداخله انسانی کمی نیاز دارد و فقط لازم است مجموعه داده مورد نظر در اختیار سیستم قرار گیرد و خود سیستم با یادگیری ماشینی، الگوریتمها را گردآوری و اصلاح خواهد کرد و به مرور زمان با دادههای ورودی بیشتر بهبود مییابد. مشتریان و کاربران میتوانند از تجربه شخصیتری نیز لذت ببرند، زیرا مدل با هر تجربهای با آن شخص، چیزهای بیشتری میآموزد.
از جنبه منفی، یادگیری ماشینی به مجموعه دادههای آموزشی بزرگی نیاز دارد که دقیق و بیطرفانه باشند. یادگیری ماشینی نیز بسته به ورودی ممکن است مستعد خطا باشد. با یک نمونه بسیار کوچک، سیستم می تواند یک الگوریتم کاملاً منطقی تولید کند که کاملاً اشتباه یا گمراه کننده است. برای جلوگیری از اتلاف بودجه یا نارضایتی مشتریان، سازمانها باید تنها زمانی به پاسخها عمل کنند که اعتماد بالایی به خروجی وجود داشته باشد.
یادگیری عمیق در مقابل یادگیری ماشینی و در مقابل شبکه های عصبی
از آنجایی که یادگیری عمیق و یادگیری ماشین به جای یکدیگر مورد استفاده قرار می گیرند، توجه به تفاوت های ظریف بین این دو ارزشمند است. یادگیری ماشینی، یادگیری عمیق و شبکه های عصبی همگی زیر شاخه های هوش مصنوعی هستند. با این حال، شبکه های عصبی در واقع زیر شاخه ای از یادگیری ماشینی هستند و یادگیری عمیق زیر شاخه ای از شبکه های عصبی است.
هم الگوریتمهای یادگیری ماشین و هم الگوریتمهای یادگیری عمیق با استفاده از شبکههای عصبی از حجم عظیم دادهها برای یادگیری استفاده میکنند. این شبکههای عصبی ساختارهای برنامه ریزی شده ای هستند که بر اساس فرآیندهای تصمیمگیری مغز انسان مدلسازی شدهاند و از لایههایی از گرههای به هم پیوسته تشکیل شدهاند که ویژگیهایی را از دادهها استخراج و در مورد این که دادهها چه چیزی را نشان میدهند، پیشبینی هایی انجام می دهند. تفاوت یادگیری عمیق و یادگیری ماشین در نحوه یادگیری الگوریتم است. یادگیری ماشینی «عمیق» میتواند از مجموعه دادههای برچسبگذاریشده، که با عنوان یادگیری نظارتشده (supervised learning) نیز شناخته میشود، برای بازخورد به خود الگوریتم استفاده می کند، اما لزوماً به یک مجموعه داده برچسبگذاری شده نیاز ندارد. فرآیند یادگیری عمیق میتواند دادههای بدون ساختار را به شکل خام (مثلاً متن یا تصاویر) دریافت و میتواند به طور خودکار بر مبنای ویژگیهایی، دستههای مختلف دادهها را از یکدیگر متمایز کند. این امر برخی از مداخلات انسانی ضروری را حذف می کند و امکان استفاده از مقادیر زیادی داده را فراهم می کند. همانطور که لکس فریدمن (Lex Fridman) اشاره می کند، می توان یادگیری عمیق را با عنوان «یادگیری ماشین مقیاس پذیر» (scalable machine learning) در نظر گرفت.

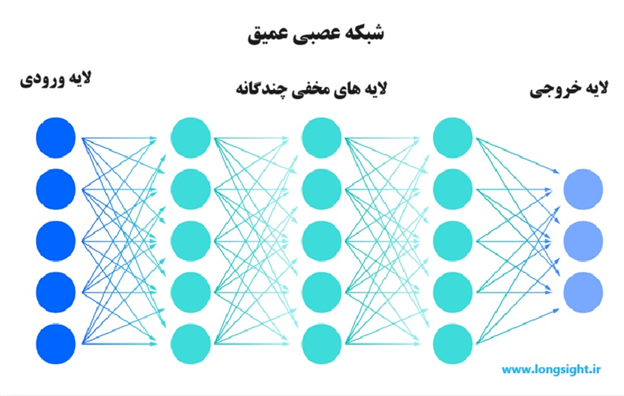
انواع شبکههای عصبی که یادگیری ماشینی و یادگیری عمیق از آنها استفاده میکنند در میزان دخالت انسان با هم تفاوت دارند. الگوریتمهای کلاسیک یادگیری ماشین با شبکههای عصبی از یک لایه ورودی و یک یا دو لایه پنهان و یک لایه خروجی استفاده میکنند. به طور معمول، این الگوریتمها محدود به یادگیری فرد ناظر هستند و دادهها باید توسط متخصصان انسانی سازماندهی یا برچسبگذاری شوند تا الگوریتم بتواند ویژگیهایی را از دادهها استخراج کند. یادگیری ماشینی کلاسیک یا «غیرعمیق» برای یادگیری بیشتر به مداخله انسان وابسته است. متخصصان انسانی مجموعه ای از ویژگی ها را برای درک تفاوت بین داده های ورودی تعیین می کنند که معمولاً برای یادگیری به داده های ساختاریافته بیشتری نیاز دارند.
شبکههای عصبی یا شبکههای عصبی مصنوعی (artificial neural networks)، از لایههای گره دار تشکیل شدهاند که شامل یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی است. هر گره یا نورون مصنوعی به دیگری متصل می شود و دارای وزن و آستانه مربوطه است. اگر خروجی هر گره بالاتر از مقدار آستانه مشخص شده باشد، با فعال شدن گره، داده ها به لایه بعدی شبکه ارسال می شوند. در غیر این صورت، هیچ داده ای توسط آن گره به لایه بعدی شبکه منتقل نمی شود. کلمه «عمیق» در یادگیری عمیق فقط به تعداد لایه های یک شبکه عصبی اشاره دارد. یک شبکه عصبی که از بیش از سه لایه تشکیل شده است (شامل ورودی و خروجی) را می توان یک الگوریتم یادگیری عمیق یا یک شبکه عصبی عمیق در نظر گرفت. شبکه عصبی که فقط سه لایه دارد، یک شبکه عصبی اولیه می باشد. یادگیری عمیق و شبکههای عصبی باعث تسریع پیشرفت در زمینههایی مانند بینش رایانه، پردازش زبان طبیعی و تشخیص گفتار میشوند. الگوریتمهای یادگیری عمیق از شبکههای عصبی عمیق استفاده میکنند یعنی شبکههایی که از یک لایه ورودی، سه یا بیشتر (اما معمولاً صدها) لایه پنهان و یک چیدمان خروجی تشکیل شدهاند. این لایههای چندگانه، یادگیری بدون فرد ناظر را امکانپذیر میکنند و استخراج ویژگیها از مجموعه دادههای بزرگ را بدون برچسب و بدون ساختار به صورت خودکار انجام میدهند. از آنجایی که به مداخله انسانی نیاز ندارد، یادگیری عمیق اساساً یادگیری ماشین را مقیاس پذیر می کند.
ظهور مدل های مولد هوش مصنوعی
هوش مصنوعی مولد (Generative AI) به مدلهای یادگیری عمیق اطلاق میشود که میتوانند دادههای خام را بگیرند (مثلاً تمام ویکیپدیا یا آثار جمعآوریشده رامبراند) و از آنها «یاد بگیرند» تا در صورت نیاز خروجیهای آماری احتمالی تولید کنند. در سطح بالاتر، مدلهای مولد نمایش سادهشدهای از دادههای آموزشی خود را رمزگذاری میکنند و از آن برای ایجاد یک اثر جدید و مشابه (ولی نه یکسان) با دادههای اصلی استفاده میکنند. مدل های مولد سال هاست که برای تجزیه و تحلیل داده های عددی در آمار استفاده می شوند. با این حال، ظهور یادگیری عمیق، گسترش آنها را به تصاویر، گفتار و دیگر انواع داده های پیچیده ممکن کرد. در میان اولین مدلهای هوش مصنوعی جهت دستیابی به یک انطباق کلی، مدل های رمزگذاری خودکار متغیر (variational autoencoders) یا VAE وجود داشت که در سال 2013 معرفی شد. مدل های رمزگذاری خودکار متغیر اولین مدلهای یادگیری عمیق بودند که به طور گسترده برای تولید تصاویر و گفتار واقعی مورد استفاده قرار گرفتند.
آکاش سریواستاوا (Akash Srivastava)، کارشناس هوش مصنوعی در آزمایشگاه هوش مصنوعی MIT-IBM Watson می گوید: «VAEها با آسانتر کردن مقیاسپذیری مدلها، دروازههای مدلسازی مولد عمیق را گشودند. بسیاری از آنچه امروز به عنوان هوش مصنوعی مولد می شناسیم از اینجا شروع شد. نمونه های اولیه این مدل ها، از جمله GPT-3، BERT، یا DALL-E 2، نشان داده اند که چه کارهایی امکان پذیر است. در آینده، مدلها برای کار بر روی مجموعه گستردهای از دادههای بدون برچسب آموزش داده میشوند که میتوانند برای کارهای مختلف با حداقل نیاز به تنظیم دقیق مورد استفاده قرار گیرند. سیستمهایی که وظایف خاصی را در یک حوزه خاص اجرا میکنند، جای خود را به سیستمهای هوش مصنوعی گستردهای میدهند که به طور کلیتری یاد میگیرند و در میان حوزه ها و مسائل کار میکنند. مدلهای بنیادی که بر روی مجموعه دادههای بزرگ و بدون برچسب آموزش دیدهاند و برای طیفی از برنامهها بهخوبی تنظیم شدهاند، محرک این تغییرات هستند. در مورد آینده هوش مصنوعی، زمانی که صحبت از هوش مصنوعی مولد به میان می آید، پیش بینی می شود که مدل های پایه و بنیادی به طور چشمگیری پذیرش هوش مصنوعی را در سازمان ها تسریع خواهند کرد. کاهش الزام به برچسبگذاری، کار را برای کسبوکارها آسانتر میکند و اتوماسیون بسیار دقیق و کارآمد مبتنی بر هوش مصنوعی، شرکتهای بسیار بیشتری را قادر خواهد ساخت تا هوش مصنوعی را در طیف وسیعتری از موقعیتهای حیاتی مأموریت های خود به کار گیرند.
کاربردهای هوش مصنوعی
امروزه برنامه های کاربردی متعددی در دنیای واقعی برای سیستم های هوش مصنوعی وجود دارد. در زیر برخی از رایج ترین مواردی که استفاده می شود تشریح شده است:
تشخیص گفتار که با نام تشخیص خودکار گفتار (ASR- automatic speech recognition)، تشخیص گفتار کامپیوتری (computer speech recognition)، یا گفتار به متن (speech-to-text) شناخته می شود، از NLP برای تبدیل گفتار انسان به نوشتار استفاده می کند. بسیاری از دستگاههای تلفن همراه برای انجام جستجوی صوتی (مثلاً Siri) تشخیص گفتار را در سیستمهای خود گنجاندهاند یا دسترسی بیشتری در مورد ارسال پیامک به زبان انگلیسی یا بسیاری از زبانهای پرکاربرد فراهم میکنند.
خدمات مشتری رابط های مجازی آنلاین و چت بات ها جایگزین ارتباط انسان ها با مشتریان می شوند. آنها به سؤالات متداول و پرتکرار (FAQ) درباره موضوعاتی مانند حمل و نقل پاسخ میدهند، یا توصیههای شخصیسازی شده، محصولات پر فروش یا اندازههای پیشنهادی برای کاربران را ارائه میدهد و طرز فکر ما را در مورد تعامل با مشتری در وبسایتها و پلتفرمهای رسانههای اجتماعی تغییر میدهد. به عنوان مثال میتوان به رباتهای پیامرسان در سایتهای تجارت الکترونیک با رابط های مجازی، برنامههای پیامرسانی مانند Slack و Facebook Messenger و کارهایی که معمولاً توسط دستیاران مجازی و دستیارهای صوتی انجام میشود، اشاره کرد.
بینش کامپیوتر (Computer vision) مصنوعی رایانهها و سیستمها را قادر میسازد تا اطلاعات معنیداری را از تصاویر دیجیتال، ویدیوها و سایر ورودیهای بصری استخراج کنند و بر اساس آن ورودیها، میتوانند اقدام کنند. توانایی این برنامه در ارائه توصیه ها، آن را از سیستم تشخیص تصویر (image recognition) متمایز می کند. بینش کامپیوتر مبتنی بر شبکه های عصبی کانولوشنال دارای کاربردهایی در برچسب گذاری عکس در رسانه های اجتماعی، تصویربرداری رادیولوژی در پزشکی و خودروهای خودران در صنعت خودروسازی می باشند.
زنجیره تامین (Supply chain) روباتیک تطبیقی (Adaptive robotics) بر روی اطلاعات دستگاه اینترنت اشیا (IoT) و داده های ساختاریافته و بدون ساختار برای تصمیم گیری مستقل عمل می کند. ابزار NLP می تواند گفتار انسان را درک کند و به آنچه به آنها گفته می شود واکنش نشان دهد. تحلیل پیشگویانه (Predictive analytic) برای پاسخگویی به تقاضا، موجودی و بهینه سازی شبکه، تعمیر و نگهداری پیشگیرانه و تولید دیجیتال بکار می رود. الگوریتمهای جستجو و تشخیص الگو (که دیگر فقط پیشبینی صرف نیستند، بلکه سلسله مراتبی هستند) دادههای زمان واقعی را تجزیه و تحلیل و به زنجیرههای تامین کمک میکنند تا به هوش افزوده حاصل از ماشین واکنش نشان دهند و در عین حال دید و شفافیت فوری را فراهم نمایند.
پیش بینی آب و هوا: مدلهای آب و هوایی که رسانه ها برای پیشبینی دقیق به آن تکیه میکنند شامل الگوریتمهای پیچیدهای است که روی ابررایانهها اجرا میشوند. تکنیکهای یادگیری ماشینی این مدلها را کاربردیتر و دقیقتر کرده اند.
تشخیص ناهنجاری: مدلهای هوش مصنوعی میتوانند مقادیر زیادی داده را بررسی کنند و نقاط داده غیرمعمول را در یک مجموعه داده کشف نمایند. این ناهنجاری ها می توانند آگاهی را در مورد تجهیزات معیوب، خطای انسانی یا نقض امنیت افزایش دهند.
در پست بعدی به کارکردهای هوش مصنوعی در مدیریت منابع انسانی خواهیم پرداخت
منابع
Berkeley, U. (n.d.). https://ischoolonline.berkeley.edu/blog/what-is-machine-learning/.
https://www.ibm.com/topics/artificial-intelligence. (n.d.).
https://www.leewayhertz.com/ai-in-human-resource-management